The Data Science of Dating Apps: A Hypothetical Case Study


When I meet other data scientists in the wild, my favorite question to ask is this:
If you could get your hands on any dataset in the world, what would it be?
For me, the answer is easy — dating app data. I've always been fascinated by how our romantic choices can be captured, quantified, and modeled. Relationships are messy and unpredictable, which make them the ultimate challenge for any data scientist. It's hard to measure attraction and compatibility, but dating apps provide a rare insight into how people express preferences and make choices in real time.
The business side of dating apps adds another layer of complexity. In theory, the goal is to help people find love. But in practice, "success" means keeping the most active users on the app. It’s a delicate balance between optimizing engagement (more ads, more paying customers, more revenue $$$) and genuine connection.
If I were a data scientist at a dating app company, these are the three main problems that I'd be most excited to explore:
- How do we detect bots and fake profiles?
- How do we build recommender systems for love?
- How do we measure success in dating apps?
Let's dive into each one.
Detecting bots and fake profiles
The first challenge for any dating app is keeping the platform real. Fake profiles, bots, and catfishing break trust. Once that happens, people stop engaging and eventually churn.
The signup process is often the best predictor of an app's vulnerability to bots. The more friction you add to signup, the more trustworthy your user base becomes — but you also risk losing new signups. Low-friction apps like OkCupid attract massive scale but need significant post-signup moderation and bot detection. High-friction apps like Raya, on the other hand, sacrifice scale for trust and authenticity. Raya's value prop is exclusivity: a secret committee of 500 members reviews applicants, and Instagram verification is required. This human vetting process dramatically reduces fraud but also limits growth – a trade-off that fits Raya’s model as an exclusive paid ($25-50/month!!) platform.
I tested the onboarding process of various dating apps and ranked their friction level from low (most vulnerable to bots) to very high (least vulnerable to bots). Here's a summary of my findings:
| App | Verification Steps | Profile Setup | Friction Level |
|---|---|---|---|
| OkCupid | Phone number verification | Optional questionnaire on preferences, beliefs, and interests | 🟢 Low |
| Tinder | Phone number verification | Requires "face check" in order to match with others. Optional bio, photos, basic demographics. | 🟡 Medium |
| Bumble | Phone number verification | Requires 1 prompt and 4 photos. Photo verfication required if photos are suspicious. | 🟡 Medium |
| Hinge | Phone number verification AND email verification | Requires 6 photos and 3 written prompts in order to match with others. | 🟠 High |
| Raya | Invitation-only, Instagram verification, human vetting process | Curated manually | 🔴 Very High |
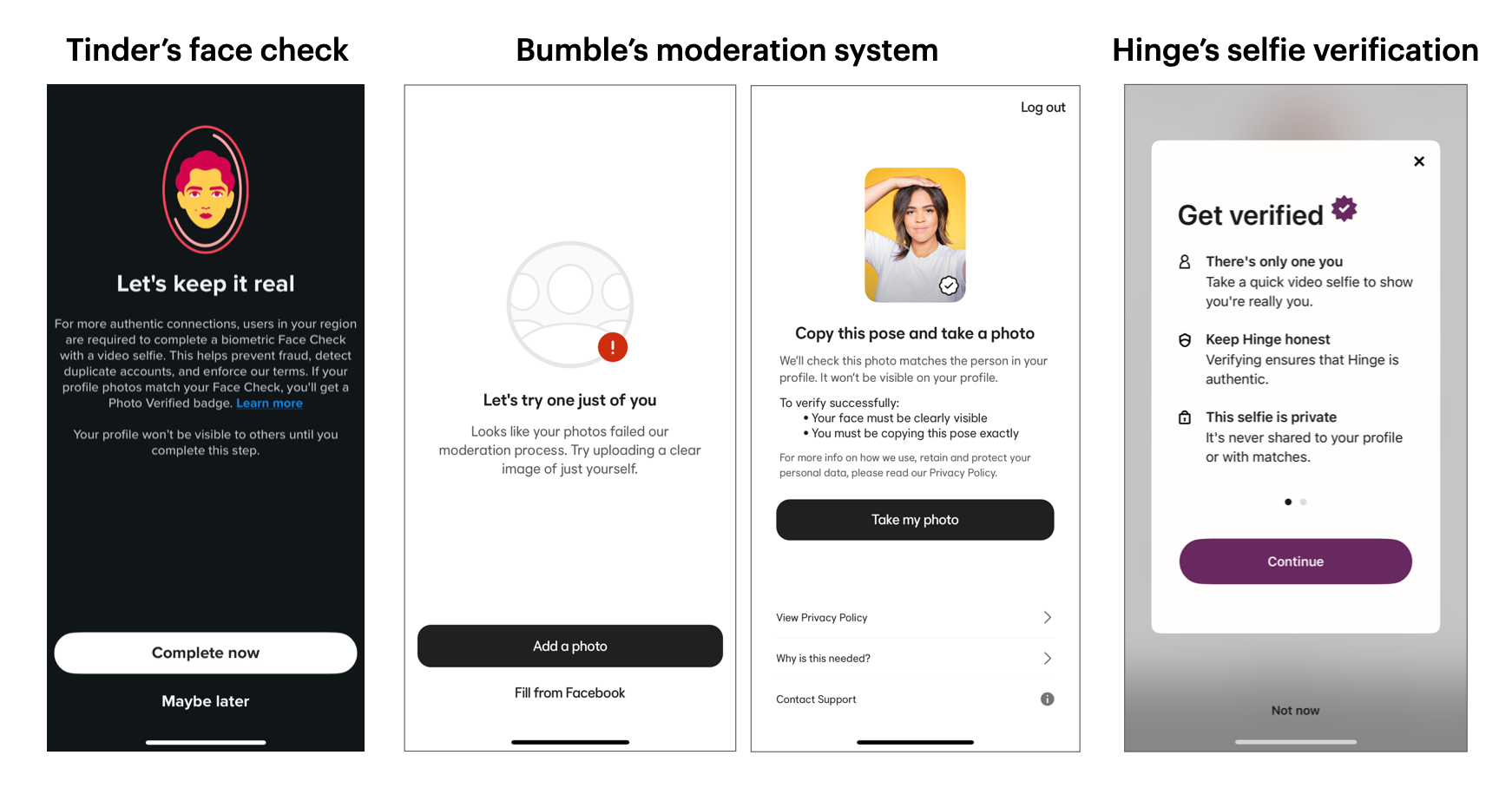
I haven't used dating apps in many years so I was surprised by how much stricter the signup process has become. Tinder now requires a biometric "face check" before you can start matching. Bumble asks for specific selfie poses to confirm your identity, and Hinge’s moderation system actually banned me a couple of days after signup.
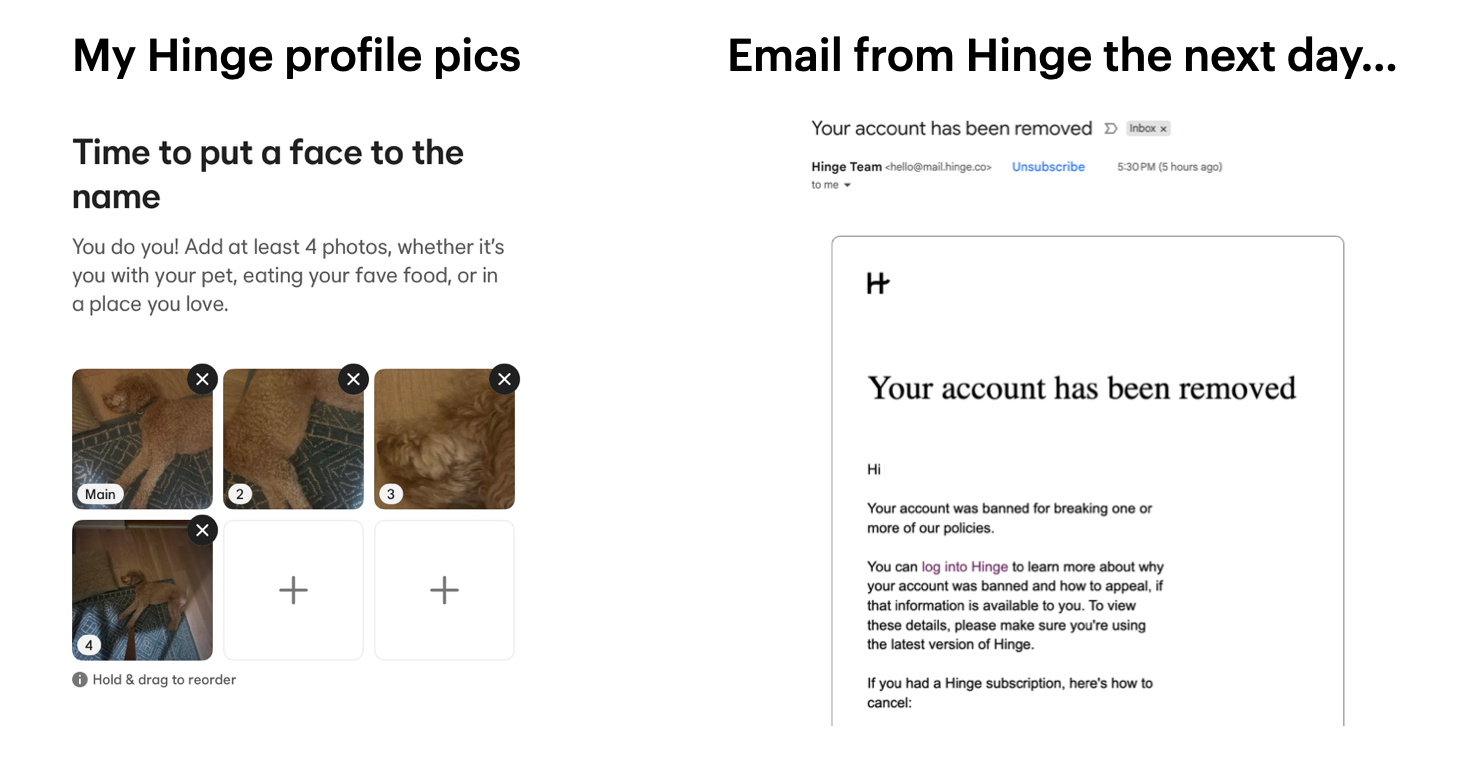
These extra verification steps show how much more emphasis platforms are placing on authenticity and safety, even if it comes at the cost of a little inconvenience during signup.
Bot detection post-signup
After signup, the focus shifts to making sure the people behind those profiles are real. I think that most dating apps combine rule-based filters with ML-driven anomaly detection to flag suspicious behavior. Some examples of suspicious behaviour could include:
- Activity patterns: Swiping at inhuman speeds, sending identical opening messages, or staying active 24/7. Also sending template-like messages that look auto-generated.
- Profile anomalies: Missing metadata, mismatched photos, stock photos, or AI-generated photos are red flags.
- Social graph signals: If we think of a dating app as a social graph, bots tend to form fragmented, one-sided connections, while real users cluster naturally around shared geography, age, or interests.
But even with these signals, bot detection is getting harder. AI-generated profiles now use realistic photos and language that can easily pass for human. And maybe that’s not entirely bad — some people are already turning to AI for companionship. As AI becomes more human, dating apps will need to define what “real” connection even means.
Recommender systems to find love
Once you’ve verified that your users are real, the next challenge is figuring out who to show them. A dating app is, at its core, a recommendation engine — except instead of recommending movies or products, it’s recommending people. But unlike Netflix or Spotify's recommender systems, which model your preferences towards a song or movie, dating apps need to model reciprocity – it needs to predict mutual attraction, not just individual preference.

After doing some user research, I've noticed that most dating apps start with a few mandatory onboarding questions — age, city, and gender preferences. These basic attributes are enough to filter a giant user base into a smaller candidate pool. Some apps also include optional questions about lifestyle, hobbies, or political views (OkCupid even has a question about sentiments towards former Canadian Prime Minister Trudeau). This data is helpful to address the cold start problem, when we know very little about new users.
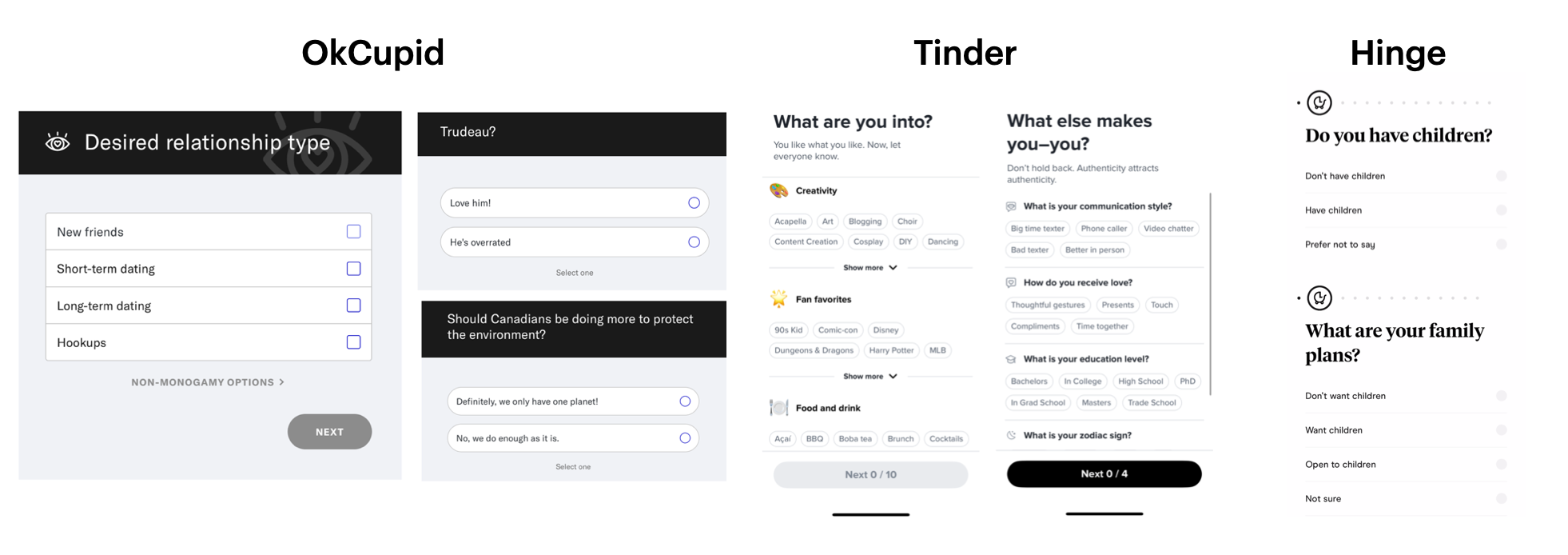
Until a user starts interacting with the app, these self-reported attributes are the only signals we have. This kind of data is called explicit feedback — it's direct input that users intentionally provide. In some cases, explicit feedback doesn’t always line up with how people actually behave. For example, a user might say they're looking for a long-term relationship, yet consistently engage with profiles that mention something casual.
This is where implicit feedback comes in. Behavioral patterns (e.g., swiping, liking, and messaging) can reveal what users are actually drawn to, not just what they say they want in the onboarding questionnaire. Over time, these behavioral signals can help measure attraction and compatibility more accurately than any signup form ever could.
In practice, most dating apps likely rely on a mix of different signals to generate recommendations:
- Content-based signals: profile "prompts", interests, and photos
- Collaborative signals: overlap in user behavior (e.g., people who liked similar profiles to yours or who were liked by the same group of users)
- Implicit feedback: interaction data such as message replies and conversation length
Since dating is messy, these systems also need real-world calibrations — balancing exposure so popular users don’t dominate, boosting recent activity, and filtering out low-quality and low-intent accounts. The result is a constant feedback loop: every swipe, match, and message helps the algorithm refine what “compatibility” looks like.
Measuring "success" on dating apps
In theory, the goal of a dating app is to help people find love. In reality, “success” depends on the company’s business model. Most dating apps operate on a freemium model where users can pay a membership fee for extra perks. These paid memberships are a major revenue driver. So if two people start a relationship and leave the app, that's two churned users and potentially less revenue. From a retention standpoint, it's paradox: the better the recommender system performs, the faster its users leave — and that success can indirectly hurt revenue.
But let's put business goals aside and assume that dating apps genuinely want to help people find love. It's still incredibly hard to know whether a match was successful or not. When two people connect and decide to meet, their conversations usually move off the app. At that point, we're dealing with a black box situation. The platform has no visibility into what happens next: did they go on a date, start a relationship, or ghost each other completely? And even if the match did lead to a relationship, how do we define success? If it lasted only a few weeks or turned into a toxic situationship, does that still count as a “win” for the recommender system?
These are the kinds of questions that fascinate me. Dating apps attempt to model human connection in all its messy, unpredictable forms—and that’s exactly what makes them so interesting to explore as a data scientist.



